
说明:以下内容摘选自笔者在高校实验室时所做的自然语言处理技术的部分综述,非技术类读者可以选择性阅读。
1.从整体上而言,目前的ChatGPT主要是延续了GPT3技术路线,依然使用了Transformer技术框架,这是一种基于注意力机制(Attention)的模型。Transformer架构允许模型并行地处理序列中的每个位置,并通过注意力机制来学习关于整个序列的依赖关系。这使得Transformer架构非常适合于自然语言处理,因为它可以有效地处理语言中的上下文和语义信息。Transformer技术可以用来替代传统的RNN模型,用于解决语言模型中的序列到序列(Seq2Seq)任务。
2.Transformer模型基于注意力机制,可以有效地捕捉句子中的依赖关系,它是一种基于深度神经网络的学习和推断输入序列和输出序列之间的映射。Transformer模型的结构主要由两部分组成:编码器和解码器。编码器的作用是将输入序列编码为一个固定长度的向量,解码后的向量解码为输出序列。Transformer模型还采用了多头注意力机制,可以同时从多个位置查看输入序列,从而捕捉更复杂的依赖关系。Transformer模型的优点是可以并RNN模型计算更快,而且可以捕捉更复杂的依赖关系,因此在自然语言处理任务中表现更好。
3.ChatGPT通过预训练大量的文本数据来学习语法和语义,并通过一个预测循环来生成文本。在接收到输入后,模型使用注意力机制从预先训练的语言数据中学到的信息来生成相应的文本输出。这种架构的优势在于,它可以根据输入的语言上下文和语义生成高质量的自然语言文本,并且可以很好地适应各种不同的任务。
4.NLP预训练技术是一种使用大型语料库训练深度学习模型的技术,以提高NLP模型的性能。它的目的是提取一些通用的模型参数,以便在任何其他任务上使用。预训练技术已经成为NLP中的一种重要技术,因为它可以减少模型训练所需的数据量,并且可以在不同的任务上复用模型参数。常见的预训练技术包括词嵌入(如Word2Vec)、语言模型(如BERT)和序列标注模型(如CRF)。
然后,ChatGPT的核心“Transformer"是什么?
说明:以下内容摘选自笔者在高校实验室时所做的自然语言处理技术的部分综述,非技术类读者可以选择性阅读。
自然语义处理NLP的Transformer是一种新的架构,旨在解决序列到序列的任务,同时轻松处理长距离依赖关系。在不使用序列对齐的RNN或的情况下计算输入和输出表示,它完全依赖于自注意力。
基本概念图如下:
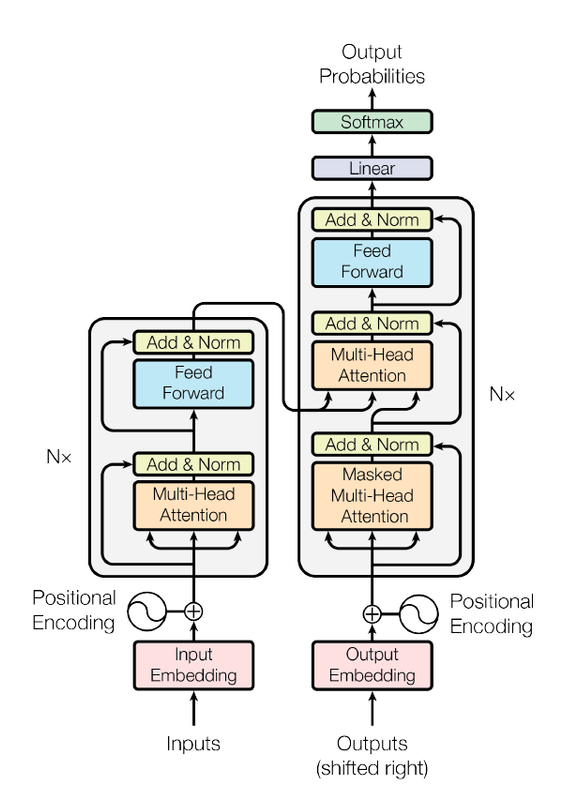
从技术逻辑上来看,Transformer模型是基于最古老的神经网络形式,即Encoder-Decoder(编码器-解码器)架构的。编码器是左边的灰色矩形,解码器在右边。编码器和解码器分别由两个和三个子层组成。多头自我意识、完全连接的前馈网络和解码器情况下的编码器解码器自我意识(称为多头注意力),具有以下可视化效果)。
·编码器:编码器负责逐步完成输入时间步长,并将整个序列编码成一个固定长度的向量,称为上下文向量。
·解码器:解码器负责在从上下文向量读取时逐步执行输出时间步长。
编码器和解码器堆栈的设置是工作机制如下图所示:
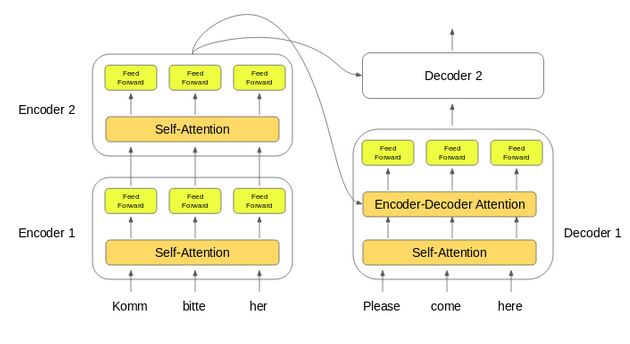
1.输入序列的词嵌入被传递到第一个编码器。
2.这些然后被转换并传播到下一个编码器。
3.编码器堆栈中最后一个编码器的输出被传递到解码器中的所有解码器。
Transformer中最核心的技术内容来自于注意力机制(Attention)。
Transformer Architecture 中的 Attention 及其工作原理:
1.首先是encoder和decoder attention层。对于这种类型的层,查询取自解码器之前的层,键和值取自编码器输出。这使得解码器的每个位置都可以关注输入序列中的每个位置。
2.第二种是encoder中包含的self-attention layer。该层从编码器之前的层的输出接收键、值和查询输入。编码器上的任何位置都可以从编码器前面的层上的任何位置接收注意力值。