
目前智能服务市场的阶梯化日益明显,以老牌厂商小i为代表,Udesk、智齿科技等,稳扎稳打、位列头部;晓多、小能科技等紧随其后,另以追一为代表的新兴公司,势头迅猛。
各厂商之间的发展虽已有明显分层,但很难形成寡头效应。因为客服行业流动的血液是企业最珍贵的数据资源,这也就意味着,行业内的技术进步和创新绝大部分来自这些生产端,且因由数据安全考虑,一般企业在壮大到一定程度后,很可能选择自建智能客服系统。再加上寒冬已至,上游的巨头们也下场加入竞争,这种状况之下,中游企业里不太能诞生一个大家耳熟能详的大厂。但这种百家争鸣的状态,却更利于市场保持活力。
第三章 2019年智能服务发展新趋势
本章节将从技术领域、人机对话模式、知识管理、智能服务范围、生产端智能化、智能语音产品,智能服务新岗位的诞生——人工智能训练师,这7个方面,来解析2019年中国智能服务的发展新趋势。
一、 技术领域
1、 备受关注的趋势转变
从自然语言处理,到深度学习的兴起,人工智能一下子掀起科技大浪潮,深度学习也基本被等同于“人工智能”。然而回望过去的一年,仔细观察会发现,更愿意在公开场合去聊AI这个概念的人,反而是不是行业的深耕者。
人工智能领域的另一概念更显生机,那就是——知识图谱。从下图“知识图谱与深度学习”的百度指数对比可看出:深度学习的受关注度从18年开始,逐渐开始小幅下降,而知识图谱的受关注度,一直在稳步缩小与深度学习间的差距,可想见的是,往后的几年里,将会迎来一场大爆发。
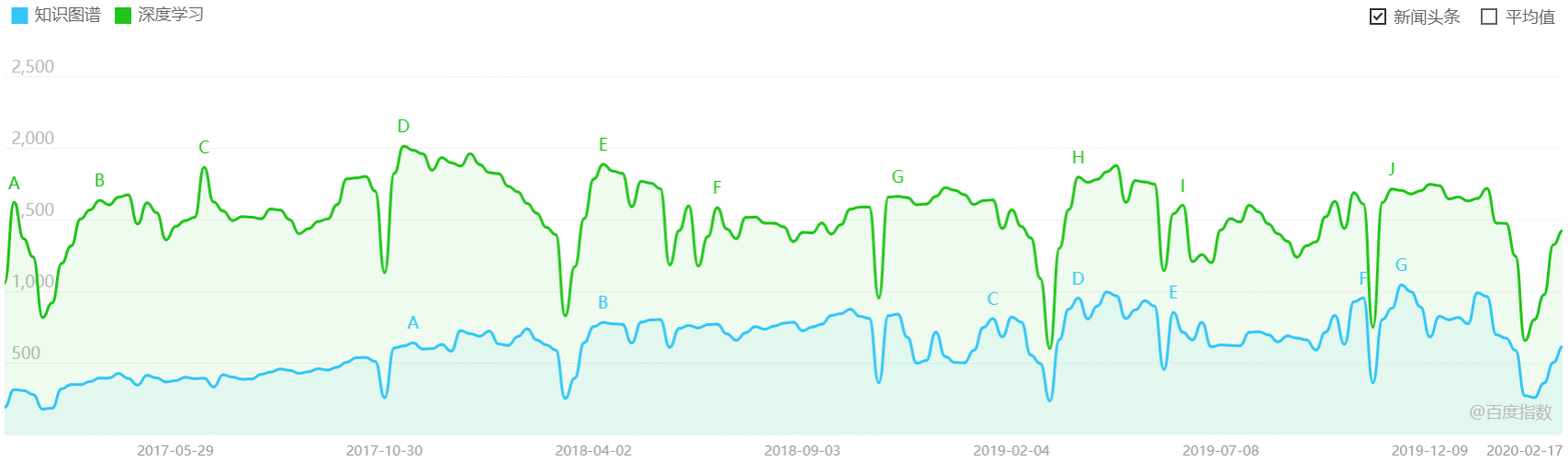
知识图谱与深度学习百度指数对比
2、 何谓知识图谱
知识图谱于2012年由Google正式发表,其初衷是为了提高搜索引擎的能力,改善搜索质量和体验。它是人工智能技术的组成部分,其强大的语义处理和互联组织能力,为智能化信息应用提供了基础。
知识图谱最核心的事情就是把数据和知识整理成图的结构,图是由边加上点组成,每个点代表这个领域的实体,每个边代表实体和实体之间的关系。
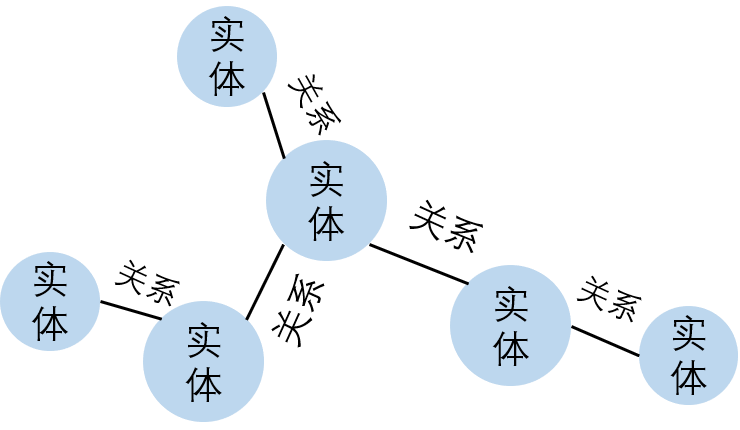
知识图谱的实体与关系图
为了能清晰地理解知识图谱的特性,我们首先来看早期使用关键词+自然语言处理的客服机器人是怎么工作的。

关键词+NLP客户对话实现流程
从上图可见,这种模式是给定自然语言问题,通过对问题进行语义理解和解析,利用知识库进行查询得出答案。基本流程是,用户提出问题,机器人分析用户问题,与知识库里的标准问题根据相似度计算后召回,然后给匹配出的问题按相似度进行排序;假设阀值设定为0.9,Q1相似度为0.8,Q2相似度为0.9,Q3相似度为0.95,此时Q1、Q2均达到阀值,那系统就输出相似度更高的Q3的答案。其特点是,输出的答案是知识库中的实体。
我们再来看知识图谱:

知识图谱客户对话实现流程
首先,用户问题中会进入图谱中,进行实体与属性的识别,例如,用户问题“我这单用了红包,还能享受返利吗”,红包和返利都是实体,而相应的抵扣条件、返利规则等,就是属性;然后进入到语义理解模型,将这个问题拆分成机器听得懂的表达,再返回图谱中按约束条件查找,如:返利条件?这个表达可能存在多个实体、多个意图,以及多个约束条件,因此还需要有一个模块将多个结果组合起来形成一个完整的语义表达式,这就是依存分析器,例如:Semantic Dependency Parser,这是一个简洁高效的模型,速度很快,效果也很好,可以用来解决复杂问题,如多实体、多约束条件、多谓词多意图等。最后,用这个语义表达在图谱中查询出的结果,例如,返利条件:未使用红包,推理出答案“您好,此单很抱歉不能享受返利了”。
由此对比可知,知识图谱输出的答案,和使用关键词+NLP有很大区别,并不是知识库预设好的答案实体,而是可推理得到的答案。原来用户问这样的问题,得到的回答是关于红包和返利的知识,需要用户自己理解后再判断一遍。而采用知识图谱后,用户得到的是确切的针对性的答案。可以看出,知识图谱很适合用来处理复杂条件、比较类、推理类的客户问题。